Super Resolution with Generative Adversarial Networks
he research conducted by looking into state-of-art papers, examing the propsed methodology, and the outcomes they recieved.
State of Art Studies
In this section, I'll give brief bullet points on the outcomes of the papers given in the titles.
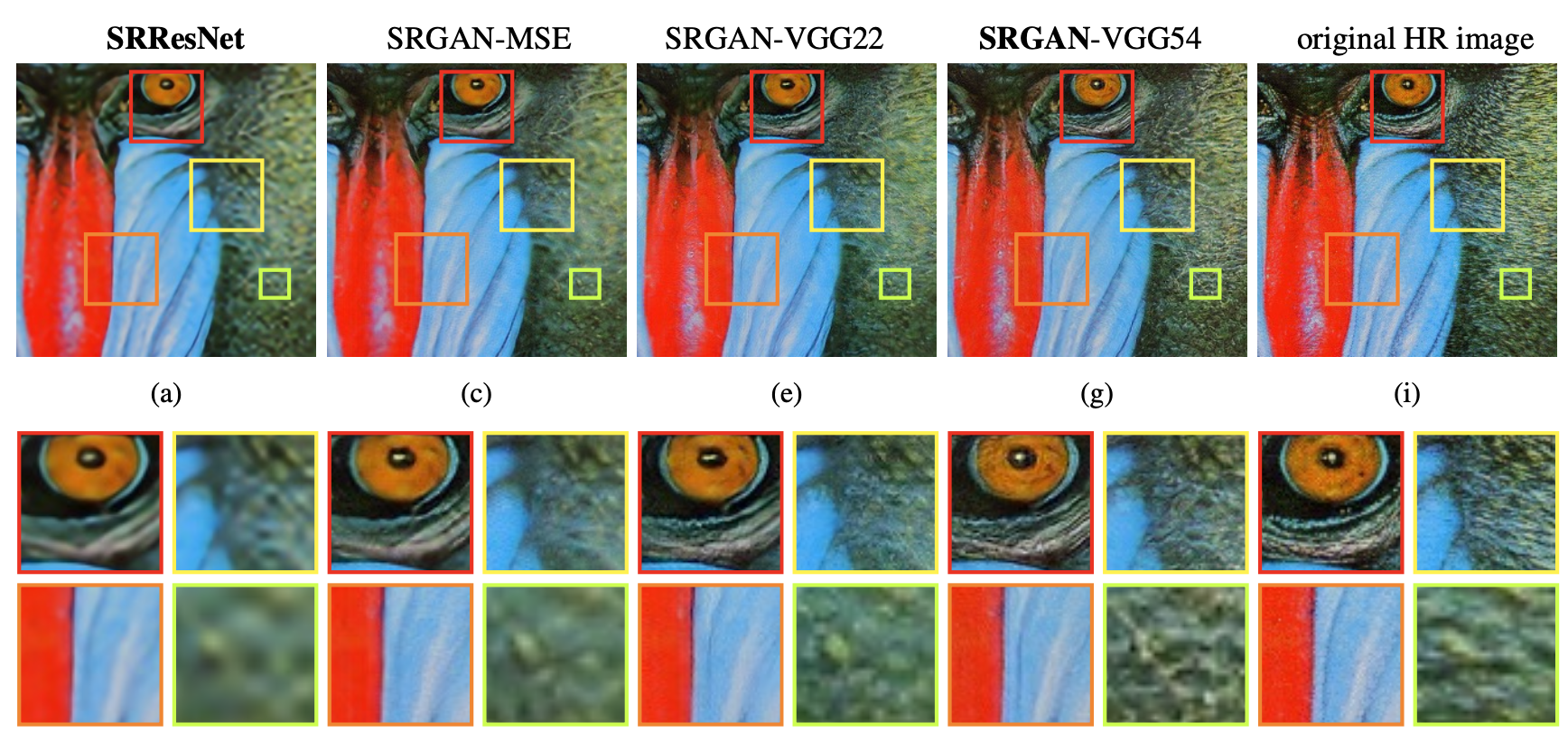
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network by Ledig at al.
- Until this point, the problem still remains: How do we recover the finer texture details when we super-resolve at large upscaling factors?
- Latest papers achieved high peak to signal ratio, but they often lack in higher frequency details and lack of fidelity.
- SRGAN technique (their method) supports 4x upscaling factors.
- A perceptual loss function which consists of an adversarial loss and a content loss. This content loss looks for the "perceptual" similarity instead of pixel based.
- Common measure on SR models is the mean square error which in decrease causes PSNR to increase. However, better PSNR or MSE does not guarantees the better perceptuality.
- Methods that predicts the SR images yields solutions with overly smooth textures.
- Deeper CNN models results better accuracy since it allows mapping of very high complexity.
- For training, low resolution images constructed by applying Gaussian blur and then downsampling the high resolution images.
- Generator network: A CNN network with skipping connections and batch normalization layers.
- Discriminator Network: A CNN-VGG network with LeakyReLU activations.
- Loss function: A VGG-19 network for content loss, and max-min for adversial loss.
- Used datasets: Set5, Set14, BSD100, BSD300. Performed scaled 4x. They trained the model with sub-samples such as 96x96 dimensions.
- Example code can be found: https://github.com/david-gpu/srez
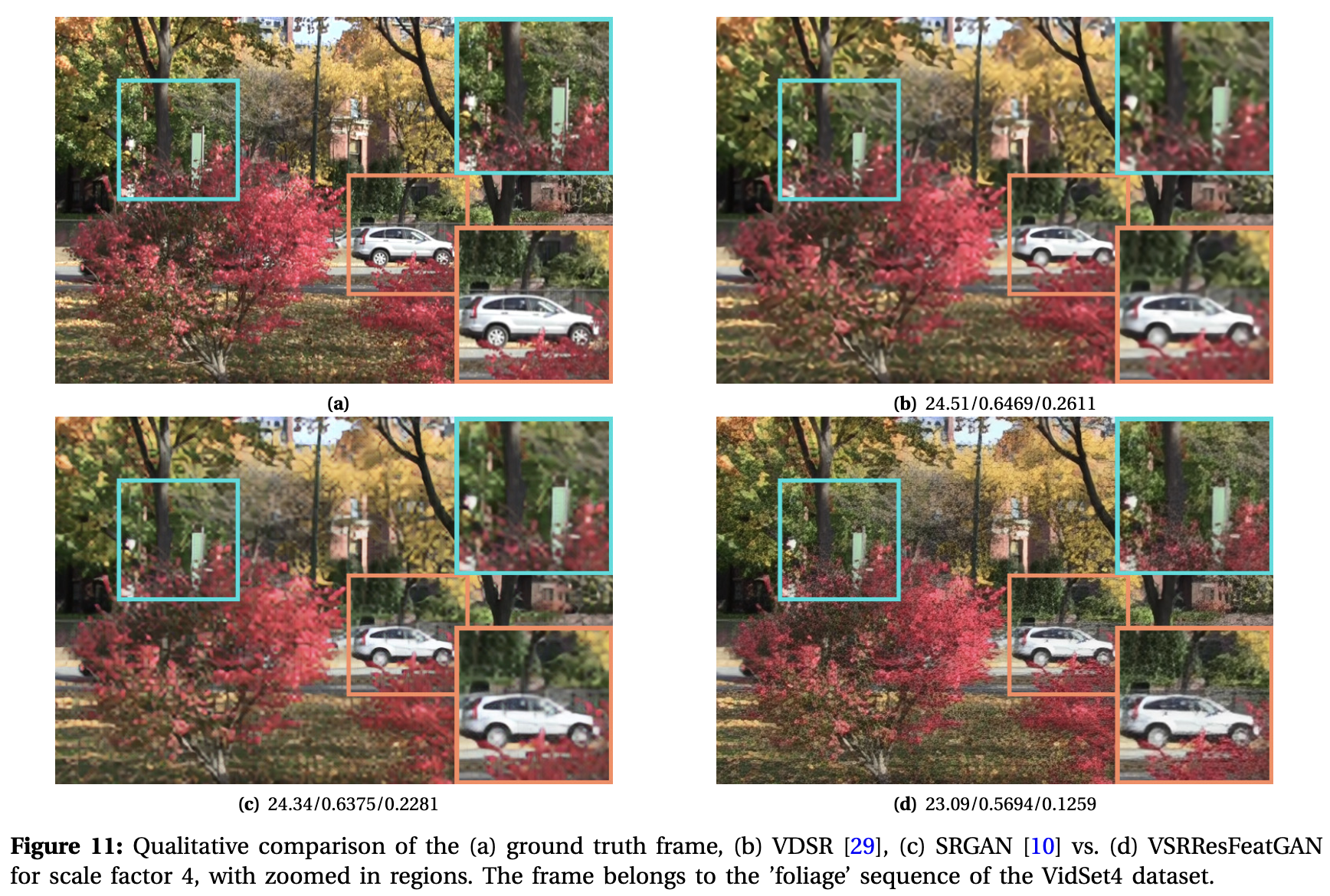
Generative Adversarial Networks and Perceptual Losses for Video Super-Resolution by Lucas et al.
- Algorithms which tackle super-resolution problem can be divded into two categories: model-pased and learning-based.
- Numerous works in the literature shown that MSE-based approaches results blurry images. Literature shows a new technique for this problem: the use of feature spaces learned by pre-trained discriminative network to compute $l_2$ distance between an estimated and ground truth high-resolution frame during training.
- Adding depth to the model increases the capacity of the model, that provides better learned solutions for the VSR problem.
- Not using the motion compensation provides the additonal benefit of significantly reducing the computational time of the propesed method.
- They modify the original GAN setting by inputting the sequence of input low-resolution frames Y to the generator instead of random vector z.
- It is shown that use of the adversarial loss alone results in the GAN learning to produce high-requency artifacts.
- Charbonnier distance instead of the traditional $l_2$ loss in pixel and feature-space as regularizers for the GAN training imporves the learning behaviour of the GAN model.
- Mynmar video sequence used. They downsampled the frames in each scene by four to obtain frames of resolution 960x540. To synthesize the correspoinding LR patches, they first performed bicubic downsampling on the HR frames at time $t-2$, $t-1$, $t$, $t+1$, $t+2$, followed by bicubic interpolation on these frames. As a result, their training dataset consists of near 1-million HR-LR pairs where each ground truth 36x36 HR patch and their corresponding 36x36 LR patches for 5 time spots.
- They firstly trained VSRResNet with traditional MSE loss, then use GAN methodology.
A Progressive Fusion Generative Adversarial Network for Realistic and Consistent Video Super Resolution by Yi et al.
- Time based methods consider frames as time-series data, and send frames through the network in a specific sequence. Space based methods take multiple frames as supplementary materials to help reconstruct the reference frame.
- Deep CNNs do not need the help of motion estimation and motion compansation. It is hown that ME&MC methods contributes little (0.01-0.04dB) to the VSR problem. The ME&MC methods tried: STMC and SPMC.
- Non-local netural networkds intends to increase the tenporal coherence among frames which means it enjoys potential to replace the complex ME&MC in VSR.
- Non-local operation aims at computing the correlation between al possible pixels within and across frames, while ME&MC intends to compensate other frames to the reference frame as close as possible.
- They propose a new loss function called Frame Variation Loss together with a single sequence training method for GAN's training.
- Having 64x64 inputs instead of 32x32, makes the VSR better.