Discrete Mathematics

Marmara University School of Engineering
Course credit: 5 ACTS
Course Lecturer: Şakir Bingöl
Last Updated: June, 24 2021.
Document created by Gökhan K.
from teacher's slides and himself's notes
with using Markdown, Typora, LaTeX/
MathJAX.
Logic
Operators
- Not – "¬p"
- Conjunction – and – "p ∧ q"
- Disjunction – (inclusive) or – "p ∨ q"
- Disjunction – (exclusive) (x/e)or – "p ⊕ q"
- Conditional statement – if … then … – "p → q"
- In the example above, p is called hypothesis and q is called conclusion.
- "p only if q" means "p → q"
- Converse of the example is "q → p"
- Contrapositive of the example is "¬q → ¬p" (Same truth table with the original statement)
- Inverse of the example is "¬p → ¬q"
- Biconditional statement – if and only if – "p ↔ q"
- Precedence of Logical Operators: ¬ > ∧ > ∨ > → > ↔
- There are bit strings which holds lots of bits. When we expand the bit operations (OR; XOR; AND) to bit string level, we call them bitwise operators. For example, 0101 1100 0100 ⊕ 1100 0000 1001 = 1001 1100 1101
- You can use bitwise and operator for masking wanted bits from the bit string. If we want to get bits[9:14] from the bit string "0111 0101 1101 1001 0010 1100", we can use the method bellow:
- 0111 0101 1101 1001 … ∧ 0000 0000 1111 0000 … = 0000 0000 1101 0000 …
Fuzzy Logic
Fuzzy logic is used in artificial intelligence. In fuzzy logic, a proposition has a truth value that is a number between 0 and 1, inclusive. A proposition with a truth value of 0 is false and one with a truth value of 1 is true. Truth values that are between 0 and 1 indicate varying degrees of truth. For instance, the truth value 0.8 can be assigned to the statement “Fred is happy,” because Fred is happy most of the time, and the truth value 0.4 can be assigned to the statement “John is happy,” because John is happy slightly less than half the time.
- The truth value of the negation of a proposition in fuzzy logic is 1 minus the truth value of the proposition.
- The truth value of the conjunction of two propositions in fuzzy logic is the minimum of the truth values of the two propositions.
- The truth value of the disjunction of two propositions in fuzzy logic is the maximum of the truth values of the two propositions.
Applications
- Translating natural language to mathematics
- Boolean searches on search engines
- Logic Puzzles
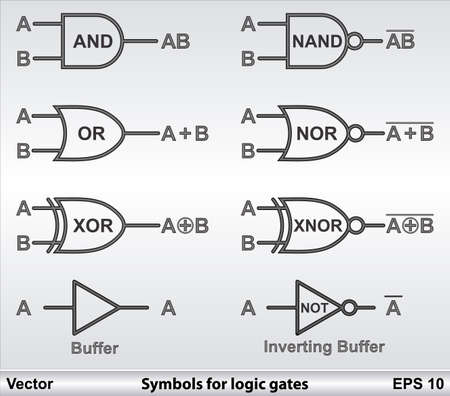
- Logic Circuits
- First time in 1938 by Claude Shanon in his MIT master's thesis.
- Shapes can be shown bellow.
Propositional Equivalences
- Tautology is the compound proposition which is always true.
- Contradiction is the compound proposition which is always false.
- The compound propositions p and q are called logically equivalent if p ↔ q is a tautology. The notation "p ≡ q" denotes that p and q are logically equivalent. Sometimes "⇔" used for the symbol.
- De Morgan's Laws states that "not and" can transform to "or", or "not or" can transform "and".
- ¬(p ∧ q) ≡ ¬p ∨ ¬q
- ¬(p ∨ q) ≡ ¬p ∧ ¬q
- Transform of if condition: p → q ≡ ¬p ∨ q
- Distributive Laws states that,
- p ∨ (q ∧ r) ≡ (p ∨ q) ∧ (p ∨ r)
- p ∧ (q ∨ r) ≡ (p ∧ q) ∨ (p ∧ r)
- Absorption laws states that,
- p ∨ (p ∧ q) ≡ p
- p ∧ (p ∨ q) ≡ p
- To make a truth table of $n$ different propositional variables, we need $2^n$ rows.

Quantifiers with Restricted Domains
- $\forall(x < 0),\ x^2>0$ is same as $\forall x(x<0 \rightarrow x^2 > 0)$.
- $\forall(y \ne 0),\ y^3 \ne 0$ is same as $\forall y(x \ne 0 \rightarrow y^3 \ne 0)$.
- $\exist(z > 0),\ z^2 = 2$ is same as $\exist z(z>0\ \and \ z^2 = 2)$
- $\forall$ and $\exist$ have higher precedence than all logical operators.
Set Theory
- $A = {a_1, a_2, a_3, ..., a_n}$ A set can be shown as like this.
- $a_1 \in A$ a is an element of A.
- Uppercase letters are used to indicate sets.
- Lowercase letters are used to indicate elements.
- $b \notin A$ b is not an element of A.
- In sets, order of the elements and frequency of an element are not important!
- Set Equality: Sets A and B are equal if and only if they contain exactly the same elements.
- $A = \emptyset$ A is an empty/null set.
- $A \subseteq B$ A is a subset of B. ($A \subseteq B \iff (x \in A \to x \in B)$)
- $A = B \iff (A \subseteq B) \and (B \subseteq A)$
- $(A \subseteq B) \and (B\subseteq C) \to A \subseteq C$
- $\forall A,\ (\emptyset \and A) \subseteq A$
- $A \subset B$ A is a proper subset of B. ($\forall x(x \in A \to x \in B) \and \exist x (x \in B \and x \notin A)$)
- If a set $S$ contains n distinct elements, $n \in N$, we call $S$ a finite set with cardinality n.
- It can be shown like $|S| = 4$ if S contains 4 elements.
- Cardinality of an empty set is 0.
- Power set of a set is described as "_all the subsets of the given set."
- $2^A$ or $P(A)$ Power set of A.
- $2^A = {B\ |\ B \subseteq A}$
Tuples
- Ordered collection of objects. Think it is a kind of set which we care about the order of the elements.
- $A = (a_1, a_2, a_3, ..., a_n)$
- Two ordered n-tuples are equal if and only if they contain exactly the same elements in the same order.
Cartesian Product of Two Sets
- $A \times B = {(a, b)\ |\ a \in A \and b \in B}$
- For example, $A = {x, y}$ and $B = {a, b, c}$, the $A \times B = {(x, a),(x, b),(x,c),(y,a),(y,b),(y,c)}$
- $A \times \emptyset = \emptyset$ and also, $\emptyset \times A = \emptyset$.
- For non-empty sets A and B, $A \ne B \iff A \times B \ne B \times A$
- $|A \times B| = |A| \cdot |B|$
Set Operations
- Union: $A \cup B = {x\ |\ x \in A ∨ x \in B}$
- Intersection: $A \cap B = {x\ |\ x \in A \and x \in B}$
- If two sets share no elements, we called them disjoint.
- $A \cap B = \emptyset$
- Difference: $A - B = {x\ |\ x \in A \and x \notin B}$
- Complement: $-A = U - A$, ($U$ is the domain of the set A.)
- Every logical expression can be transformed into an equivalent expression in set theory and vice versa.
Functions
- A function is a assignment of exactly one element of set B to the each element of set A.
- If $f$ is a function from A to B, $f: A \to B$.
- Domain is $A$.
- Co-domain is $B$.
- $f: A \to B$ maps $A$ to $B$.
- If $f(a) = b$,
- Image: $b$
- Pre-image: $a$.
- Range is the set of all images of elements in the domain.
- If we only regard a subset $S \subseteq A$, the set of all images of the elements $s \in S$ is called the image of $S$. We denote it by $f(S)$.
- $f(S) = {f(s)\ |\ s \in S}$
Function Operations
- Summation: $(f_1 + f_2)(x) = f_1(x) + f_2(x)$
- Multiplication: $(f_1 \cdot f_2)(x) = f_1(x) \cdot f_2(x)$
- Note that, subtraction is a type of summation and division is a type of multiplication
- Composition of two functions: $(fog)(a) = f(g(a))$
Sequences
- One can describe it as ordered list of elements.
- It is denoted by $a_r$.
- They generally represented by equations.
- Strings are also sequences.
- Gauss's Sum Formula
$$
\sum^n_{j=1}j = \frac{n(n+1)}{2}
$$
Geometric Progression
- A sequence of the form $a, ar, ar^2, ar^2, ...$ and $a, r \in \real$.
- Can be rewritten as $f(x) =a\cdot r^x$.
Arithmetic Progression
- A sequence of the form $a, a+d, a+2d, ...$ and $a, d \in \real$.
- Can be rewritten as $f(x) = a +dx$.
- A sequence can be represented with the formula in terms of another term. $a_n = a_{n-1} + 3$.
- Fibonacci Sequence is $f_n = f_{n-1} + f_{n-2}$ and $f_0 =0, f_1 = 1$.
Geometric Series
- The sums of geometric progressions.
Algorithms
An algorithm is a finite set of precise instructions for performing a computation or for solving a problem.
Properties of the algorithms are
- Input from a specified set,
- Output from a specified set,
- Definiteness of every step in the computation,
- Correctness of output for every possible input,
- Finiteness of the number of calculation steps,
- Effectiveness of each calculation step,
- Generality for a class of problems.
Algorithm Examples in the Lectures
- Finding the max of the n-number (W3L2 12:30).
- Linear search (W3L2 17:00)
- Binary search (W3L2 25:00)
- The maximum difference between any two elements in given list (W3L3 30:15)
- The maximum difference between any two elements in given list (W3L3 32:45)
- The euclidean algorithm (W4L2 28:50)
- Base b representation (W4L2 39:43)
- Add two binary numbers (W4L2 53:30)
Efficiency of Algorithms
We have two key concepts: storage and calculation time. But of course there is a mathematical way to represent it. We can measure the time-space complexity.
- Determine the worst-case. (For example, the worst case in linear search is if the searched element is not in the list.)
- Find the equation of worst-case for $n$ inputs. (For example, if the algorithm has 3 loops with $n$ iteration and then a if statement with one condition, it will be $3n+2$.)
The Growth of Functions (Big-O)
$f(x)$ is $O(g(x))$ if there are constants $C$ and $k$ such that, $|f(x)| \le C\cdot |g(x)|$ whenever $x \gt k$. For example, $f(x) = x^2 + 2x+ 1 \to O(x^2)$
-
If $f(x) \to O(x^2)$, it is also $O(x^3)$.
-
For any polynomial with $n$-degree, it is $O(x^n)$.
-
If $f_1(x) \to O(g(x))$ and $f_2(x) \to O(g(x))$ then $(f_1+f_2)(x) \to O(g(x))$.
-
If $f_1(x) \to O(g_1(x))$ and $f_2(x) \to O(g_2(x))$ then $(f_1+f_2)(x) \to O(max(g_1(x), g_2(x))$.
Number Theory
It is about integers and their properties.
Divisibility
- $a, b \in Z \text{ and } a \ne 0 \to$ $a|b$ (meaning: $a$ divides $b$ ) if there is an integer $c$. ($b = a\cdot c$)
- $a$ is a factor of $b$.
- $b$ is a multiple of $a$.
- If $a$ does not divide $b$, we can represent it as $a \text{X} b$.
- Some of the properties:
$$
(a|b) \and (a|c) \to a|(b+c)
$$
$$
a|b \to a|bc
$$
$$
(a|b) \and (b|c) \to a|c
$$
- For $a \in Z$ and $d \in Z^+$, we can say that $a = d\cdot q + r$.
- d is called the divisor,
- a is called the dividend,
- q is called the quotient,
- r is called remainder.
Primes
- A positive integer $p$ greater than 1 is called prime if the only positive factors of $p$ are 1 and $p$. If a number is not prime, then it is a composite.
- Every positive integer can be written uniquely as the product of primes.
- If $n$ is a composite integer, then $n$ has a prime divisor less then or equal $\sqrt{n}$.
- The number of primes not exceeding $x$ can be approximated by $\frac{x}{lnx}$.
- The probability that an integer $n$ is prime is also approximately $\frac{1}{ln(n)}$. But, by choosing only odd numbers, we double our chances of finding a prime.
Greatest Common Divisors and Least Common Multiple
- The largest integer $d$ such that $d | a$ and $d|b$ is called the greatest common divisor of a and b.
- GCD is denoted by $gcd(a, b)$.
- The integers $a$ and $b$ are relatively prime if their greatest common divisor is 1.
- The least common multiple of the positive integers a and b is the smallest positive integer that is divisible by both $a$ and $b$.
- LCM is denoted by $lcm(a, b)$.
- $a\cdot b = gcd(a, b) \cdot lcm(a, b)$
Modular Arithmetic
- Let $a, b \in Z$ and $m \in Z^+$, we say that a is congruent to b modulo m if m divides (a-b).
- This notation used for this purpose, $a \equiv b\ (mod\ m)$.
- Let $m$ be a positive integer. If $a \equiv b\ (mod\ m)$ and $c \equiv d\ (mod\ m)$ then,
- $a+c \equiv b+d\ (mod\ m)$
- $ac \equiv bd\ (mod\ m)$
- Let $m$ be a positive integer and let $a$ and $b$ be integers. Then,
- $(a+b)\ mod\ m = ((a\ mod\ m) + (b\ mod\ m))\ mod\ m$
- $ab\ mod\ m = ((a\ mod\ m)(b\ mod\ m))\ mod\ m$
- There is an arithmetic sign, modulo $m$.
- $a +_m b = (a+b)\ \textbf{mod}\ m$
- $a \cdot_m b = (a\cdot b)\ \textbf{mod}\ m$
- $...$
The Euclidean Algorithm
- "Why does it works?" Check out page 267.
- Let $a = bq + r$, where $a, b, q$ and $r$ are integers. Then $gcd(a, b) = gcd(b,r)$.
- For example, find the greatest common divisor of 414 and 662.
- 662 = 414 $\cdot$ 1 + 248
- 414 = 248 $\cdot$ 1 + 166
- 248 = 166 $\cdot$ 1 + 82
- 166 = 82 $\cdot$ 2 + 2
- 82 = 2 $\cdot$ 41 + 0
- Hence, $gcd(414, 662) = 2$, because 2 is the last nonzero remainder.
- Complexity of the euclidean algorithm where $a > b$ is $O(log\ b)$.
- If $a$ and $b$ are positive integers, then integers $s$ and $t$ such that $gcd(a, b) = sa + tb$ are called Bezout coefficients of $a$ and $b$.
- Let m be a positive integer and let a, b, and c be integers. If $ac \equiv bc$ (mod $m$) and $gcd(c, m) =1$, then $a \equiv b$ (mod $m$).
Representations of Integers
-
For base $10$, $859 = 8 \cdot 10^2 + 5 \cdot 10^1 + 9 \cdot 10^0$.
-
Another popular bases are binary, octal, and hexadecimal.
Induction and Recursion
Arguments
- Validness and correctness is different things. One argument might be valid but it doesn't mean that its conclusion is true.
- p: "It is raining today.", q: "We will not have a barbecue today.", r: "We will have a barbecue tomorrow.". Then, $p \to q\hspace{10pt} q \to r \hspace{10pt} \dot{.\hspace{.001pt}.} \hspace{10pt} p \to r$.
Prove Methods
- Direct Proof: An implication if p then q can be proved by showing that if p is true then q is also true.
- Indirect Proof: An implication if p then q is equivalent to its contrapositive. Therefore we can prove if p then q by showing that whenever q is false, then p is also false.
- Induction: If we have a propositional function $P(n)$, and we want to prove $P(n)$ is true for any natural number $n$, one do the followings:
- Show that $P(0)$ is true.
- Show that if $P(n)$ then $P(n+1)$ for any $n\in N$.
- Then $P(n)$ must be true for any $n \in$ N.
Recursive Definitions
- The concept is very related to mathematical induction. It is an object is defined in terms of itself.
- We can recursively define sequences, functions and sets.
- One can define a recursive function as like this. Firstly, specify the value of the function at zero. Then give a rule for finding its value at any integer from its values at smaller integers.
Inclusion and Exclusion
- The Pigeonhole Principle states that if N objects are placed into k boxes, then there is at least one box containing at least ceil(N/k) of the object. Cel() means if it's decimal, choose the upper integer.
- If we want to choose R elements in N-number set, and we want them to be ordered (no replacement), we have to use permutation. $P(n, r)$.
$$
P(n,r) = n(n-1)(n-2) ... = \frac{n!}{(n-r)!}
$$
-
If we want to choose R elements in N-number set, and we don't want them to be ordered (replacement is okay), we have use combination. $C(n,r)$. The $r!$ in the formula is the total number of orders of R elements. When we divide them, we get the choosing part with discarding the orders. You can also think that as the subsets of a set.
$$
C(n,r) = \frac{P(n,r)}{r!} = \frac{n!}{(n-r)!\cdot r!}
$$ -
Pascal Identity states that $C(n+1, k) = C(n, k-1) + C(n,k)$ if $n \ge k$. Pascal's Triangle uses this principle.
-
Binomial Expression of any $(a+b)^n$ can be shown bellow. It is also known as Binomial Theorem.
$$
(a+b)^n = \sum^n_{j=0}C(n,j)\cdot a{n-j}bj
$$
Discrete Probability
- Experiment is a procedure that yields one of a given set of possible outcomes. Sample Space is the set of possible outcomes. Think that, in set theory,
- Sample Space $S$ $\to$ Universe
- Outcome $s$ $\to$ Element
- Event $E$ $\to$ Subset
- Mutually Exclusive Events $E_1 \cap E_2 = \emptyset$ $\to$ Disjoint Events
- Impossible Events $\emptyset$ $\to$ Null Sets
- Simple Event $E={s} $$\to$ Simple Set
- You will use combination and permutation in order to find outcomes' count.
- Complementary of any event is $p(-E)=1-p(E)$.
- $p(E_1 \cup E_2) = p(E_1) + p(E_2) - p(E_1 \cap E_2)$
- If the outcomes of the experiment is not equally likely, we assign a probability$p(s)$ to each outcome $s \in S$. These conditions must be met.
- $0 \le p(s) \le 1$ for each $s \in S$
- $\sum_{s \in S} p(s) = 1$
Conditional Probability
- We can say that conditional probability is the probability of A if its depends on B. We will consider p(A) in the sample space of B.
$$
p(A|B) = \frac{p(A\cap B)}{p(B)}
$$
- If B is independent from the A, then we can say that $P(A|B) = P(A)$. Because what happens to B won't change A. The events A and B are said to be independent if and only if $p(A \cap B) = p(A)\cdot p(B)$.
Bernoulli Trails
- If we have two possible outcomes, each experiment called as Bernoulli trail. Often we are interested in the probability of exactly k successes when an experiment consist of n independent Bernoulli trials.
$$
p[k] = C(M,k)\cdot p^k\cdot (1-p)^{M-k}
$$
- The formula above give us the probability of $k$ success in M tries. It is called as Binomial Law. Since we want exactly $k$ times success, it means that we also want $M-k$ times failures. It is the part $(1-p)^{M-k}$.
Random Variables
- In some experiments, it is useful to give numbers to the non-number outcomes. Think heads and tails, we can give heads 1 and tails 0. This is called as random variable.
- Another example is the game of rock-paper-scissors. There is three outcomes: A win, B win and no one wins. We can give them numbers as $X(a,b) = {1, 0, -1}$:
- 1, if player A wins;
- 0, if A and B choose the same symbol;
- -1, if player B wins.
- Random variables are functions, not variables, and they are not random, but map random results from experiments onto real numbers in a well-defined manner.
- Once we assign random variables to our outcomes, we can use statistics now. Like finding mean (average) and variant.
Expected Value
- The expected value (or the average value) of the random variable $X(s)$ on the sample space S is equals to,
$$
E(X) = \sum_{s\in S}X(s)p_X(s)
$$
- If X and Y are the random variables on a sample space $S$, then $E(X+Y)=E(X)+E(Y)$. You can generalise this.
- Linearity principle states that $E(aX+b) = a\cdot E(X)+b$.
- The random variables X and Y on a sample space S are independent if
$$
p[(X(s)=r_1) \and (Y(s)=r_2)] = p[(X(s)=r_1)] \cdot p[(Y(s)=r_2)]
$$
- If X and Y are independent random variables on a sample space S, then
$$
E(X\cdot Y) = E(X) \cdot E(Y)
$$
Variance
- It is about the distribution of the outcomes.
- Let $X$ be a random variable on a sample space $S$. The variance of $X$, denoted by $V(X)$, is
$$
V(X) =\sum_{s \in S}\left[X(s)-E(X)\right]^2\cdot p(s)
$$
- The standard deviation of $X$, denoted by $\sigma(X)$, is defined to be the square root of $V(X)$. $\sigma(X) = \sqrt{V(X)}$.
- $V(X+Y) = $V(X) + V(Y) (it can be generalised)
Relations
All the text here are directly copied from the Discrete Mathematics and its Applications book by Rosen.
- (Jason Goodfriend, CS518) and (Deborah Sherman, CS518) belong to R. If Jason Goodfriend
is also enrolled in CS510, then the pair (Jason Goodfriend, CS510) is also in R. However,
if Deborah Sherman is not enrolled in CS510, then the pair (Deborah Sherman, CS510) is
not in R. - Let A = {0, 1, 2} and B = {a, b}. Then {(0, a), (0, b), (1, a), (2, b)} is a relation from A to B.
This means, for instance, that $0 R a$ is correct, but $1 R b$ is not correct. - A relation on a set A is a relation from A to A.
- A relation R on a set A is called reflexive if (a, a) ∈ R for every element a ∈ A.
- A relation R on a set A is called symmetric if (b, a) ∈ R whenever (a, b) ∈ R, for all a, b ∈ A.
A relation R on a set A such that for all a, b ∈ A, if (a, b) ∈ R and (b, a) ∈ R, then a = b
is called antisymmetric. - Antisymmetric means that there is no pair of elements a and b with a = b such that both (a, b) and (b, a) belong to the relation.
- A relation R on a set A is called transitive if whenever (a, b) ∈ R and (b, c) ∈ R, then (a, c) ∈ R, for all a, b, c ∈ A. The relation R on a set A is transitive if and only if $R^n$ ⊆ $R$ for n = 1, 2, 3, . . . .
- Let R be a relation from a set A to a set B and S a relation from B to a set C. The composite of R and S is the relation consisting of ordered pairs (a, c), where a ∈ A, c ∈ C, and for which there exists an element b ∈ B such that $(a, b) ∈ R$ and $(b, c) ∈ S$. We denote the composite of R and S by S ◦ R. Let $R = {(1, 1), (2, 1), (3, 2), (4, 3)}$. Because $R^2$ = R ◦ R, we find that $R^2 = {(1, 1), (2, 1), (3, 1), (4, 2)}$. Furthermore, because $R^3$ = $R^2$ ◦ R, $R^3 = {(1, 1), (2, 1), (3, 1), (4, 1)}$. Let R be an n-ary relation and C a condition that elements in R may satisfy. Then the selection operator $s_C$ maps the n-ary relation R to the n-ary relation of all n-tuples from R that satisfy the condition C.
- Projections are used to form new n-ary relations by deleting the same fields in every record of the relation. The projection $P_{i_1 i_2 ,...,i_m}$ where $i_1 \lt i_2 \lt · · · \lt i_m$ , maps the n-tuple $(a_1 , a_2 , . . . , a_n )$ to the m-tuple $(a_{i1} , a_{i2} , . . . , a_{im})$, where $m \le n$. In other words, the projection $P_{i_1 ,i_2 ,...,i_m} $deletes $n−m$ of the components of an n-tuple, leaving the $i_1$th, $i_2$th, . . . , and $i_m$th components.
- The join operation is used to combine two tables into one when these tables share some
identical fields. For instance, a table containing fields for airline, flight number, and gate, and
another table containing fields for flight number, gate, and departure time can be combined into
a table containing fields for airline, flight number, gate, and departure time.
Relational Databases
A database consists of records, which are n-tuples, made up of fields. Relations used to represent databases are also called tables, because these relations are often displayed as tables. A domain of an n-ary relation is called a primary key when the value of the n-tuple from this domain determines the n-tuple. That is, a domain is a primary key when no two n-tuples in the relation have the same value from this domain. Records are often added to or deleted from databases. Because of this, the property that a domain is a primary key is time-dependent. Consequently, a primary key should be chosen that remains one whenever the database is changed. The current collection of n-tuples in a relation is called the extension of the relation. The more permanent part of a database, including the name and attributes of the database, is called its intension. When selecting a primary key, the goal should be to select a key that can serve as a primary key for all possible extensions of the database. To do this, it is necessary to examine the intension of the database to understand the set of possible n-tuples that can occur in an extension.
Representation as Matrices
- Matrix representation have 1's in the relations and 0's for non-relations. Think it is like a table.
- R is symmetric if and only if $M_R = (M_R)^t$ , that is, if $M_R$ is a symmetric matrix.
- The matrix of an antisymmetric relation has the property that if $m_{ij} = 1$ with
$i = j$ , then $m_{ji} = 0$. - $M_{R_1 \cup R_2} = M_{R1} \or M_{R2}$
- $M_{R_1 \cap R_2} = M_{R1} \and M_{R2}$
- $M_{BoA} = M_A o M_B$
- $M_{R^n}$ means the n-th boolean product of $M_R$'s.
Closures
- If there is a relation $S$ that contains $R$ and has property $P$, and $S$ is a subset of every relation that contains $R$ and has property $P$, then $S$ is called the closure of $R$ with respect to $P$.
- In order the find closure of property Y on a relation set of A (which set A doesn't follow property Y), you have to find the elements which should be added to make that set A follows property Y.
- A path from $a$ to $b$ in the directed graph $G$ is a sequence of one or more edges $(x_0, x_1)$, $(x_1, x_2)$, $...$,$(x_{n-1}, x_n)$ in $G$, where $x_0 = a$ and $x_n = b$.
- Let $R$ be a relation on a set $A$. The connectivity relation $R^*$ consists of the pairs $(a,b)$ such that there is a path of length at least one from $a$ to $b$ in $R$.
- $R^n$ consists of the pairs $(a,b)$ such that $a$ and $b$ are connected by a path of length $n$.
$$
R^* = \bigcup\infty_{n=1}Rn
$$ - If a path from $a$ to $b$ visits any vertex more then once, it must include at least one circuit. These circuits can be eliminated from the path, and the reduced path will still connected $a$ to $b$
- A relation on a set A is called an equivalence relation if it is reflexive, symmetric, and transitive.
- Let $R$ be an equivalence relation on a set $A$. The set of all elements that are related to an element a of $A$ is called the equivalence class of $a$. The equivalence class of a with respect to R is denoted by $[a]_R$.
- To be a portion set of a equivalence class, the set must include every element, the set mustn't have another element which is not in equivalence class, the set must not contain repetitive elements (inner sets in the set interception must be empty set), and the set does not contain empty set.
- A relation $R$ on a set is called partial ordering or partial order if it is reflexive, antisymmetric, and transitive.
Graphs
- A simple graph is just like a directed graph but without specified direction of its edges. Multiple connections between vertices in a simple graph is impossible to do.
- Multi-graphs are the life-savers when we need multiple connections. The difference between a simple graph and multi-graph is that, the multi-graph has a functional connection between its edges.
- The edges $e_1$ and $e_2$ are called multiple or parallel edges if $f(e_1) = f(e_2)$. Think it is as, the highways between Tekirdağ and İstanbul. You can use both highways since the connection end-points are the same. There are two ways to go Istanbul from Tekirdağ, and vice versa. Vertices is the cities, and edges are the roads.
- No loops are allowed in multi-graphs. For example, from İzmir to İzmir.
A multigraph G = (V, E) with vertices V = {a, b, c, d}, edges E = {1, 2, 3, 4, 5}, and function f with f(1) = {a, b}, f(2) = {a, b}, f(3) = {b, c}, f(4) = {c, d}, and f(5) = {c, d}.
Means:
* There is a path between A and B called "1".
* There is a path between A and B called "2".
* There is a path between B and C called "3".
* There is a path between C and D called "4".
* There is a path between C and D called "5".
- If we want to define loops, we need a pseudo-graph.
- Directed graph consists of a set $V$ (vertices) and a set $E$ (edges) that are ordered pairs of elements in $V$. Also, there is a directed multi-graph which has directed arrows and uses multi-graph rules.
A directed multi-graph G with vertices V = {a, b, c, d}, edges E = {1, 2, 3, 4, 5}, and function f with f(1) = (a, b), f(2) = (b, a), f(3) = (c, b), f(4) = (c, d), and f(5) = (c, d).
* There is a path from A to B called "1".
* There is a path from B to A called "2".
* There is a path from C to B called "3".
* There is a path from C to D called "4".
* There is a path from C to D called "5".
- Two vertices $u$ and $v$ in an undirected graph $G$ are called neighbours or adjacent in $G$ if ${u, v }$ is an edge in $G$. If $e = {u, v}$, the edge $e$ is called incident with the vertices $u$ and $v$. The edge $e$ is also said to connect $u$ and $v$. The vertices $u$ and $v$ called endpoints of edge $e$.
- The degree of a vertex in an undirected graph is the number of edges incident with it. A loop is counted twice. One can cont the lines touches that point. It is shown as $deg(v)$.
- If $deg(v) = 0$, it is isolated.
- $deg(v) = 1$, it is pendant.
- The Handshaking Theorem says that if $G=(V,E)$ is a undirected graph with $E$ edges set which has $e$ element.
$$
2\cdot e = \sum_{v \in V} deg(v)
$$
-
An undirected graph has an even number of vertices of odd degree.
-
When $(u, v)$ is an edge of the graph $G$ with directed edges, $u$ is said to be adjacent to $v$, and $v$ is said to be adjacent from $u$. The vertex $u$ is called the initial vertex of $(u, v)$, and $v$ is called the terminal vertex of $(u, v)$.
-
In-degree of a vertex $v$ in a directed edges is the number of edges with $v$ as their terminal vertex (incoming arrows). It is denoted by $deg^-(v)$. Out-degree of $v$, denoted by $deg^+(v)$, is the number of edges with $v$ as their initial vertex (going arrows).
-
Let $G=(V,E)$ be a graph with directed edges. Then,
$$
\sum_{v \in V} deg^-(v) = \sum_{v \in V} deg^+(v) = |E|
$$
- The complete graph on n vertices, denoted by $K_n$, is the simple graph that contains exactly one edge between each pair of distinct vertices. The cycle graph $C_n$, is a circular graph (it may be a square, a pentagram...) which has minimum 3 vertices. The wheel graph $W_n$ can be created with adding an additional vertex to the cycle graph and connecting this new vertex to each vertex. The n-cube graph, denoted by $Q_n$, has vertices representing the $2^n$ bit strings of length $n$. $Q_1$ is a line, $Q_2$ is a square, $Q_3$ is a cube.
- A simple graph is called bipartite if it can be divided two graphs which the vertices in any subset is not connected to a vertex in the same subset. They can only connected to the vertices in the other part. (other subset graph). Complete bipartite graphs are the graphs that has its vertex set partitioned into two subsets of $m$ and $n$ vertices, respectively. It is denoted by $K_{m, n}$ Two vertices are connected if and only if they are in different subsets.
- A sub-graph is a part of the main graph. It does not need to have all edges inside the selection of vertices.
- The union of the graphs are the combination of that graphs. It is nothing fancy.
- The adjacency matrix A of G ($A_G$) is described as $A_G = [a_{ij}]$. Adjacency matrices of undirected graphs are always symmetric. If there are more than one edge between vertices, we put the number of edges in particular position in the adjacency matrix of the graph.
$$
a_{ij} = 1 \to \text{if } {v_i, v_j} \text{ is an edge of G} \
a_{ij} = 0 \to \text{otherwise}
$$
- The incidence matrix M of G, $M = [m_{ij}]$. The rows are vertices and the columns are edges. Hence, we need to numberize the edges.
$$
m_{ij} = 1 \to \text{if edge $e_j$ is incident with $v_i$} \
m_{ij} = 0 \to \text{otherwise}
$$
- The definition of isomorphism of graphs is very complex. Therefore, I'm going to use the easier explanation. $G_1$ and $G_2$ are isomorphic if their vertices can be ordered in such a way that the adjacency matrices $M_{G_1}$ and $M_{G_2}$ are identical. From a visual point, $G_1$ and $G_2$ are isomorphic if they can be arranged in such a way that their displays are identical.
- There are $n!$ possible isomorphisms that two $n$ vertices simple graphs have.
- For isomorphism of two graphs, these rules must be obeyed: The same number of vertices, the same number of edges, the same degrees of vertices.
- A path is continues edges from one vertex to another (not neighbour of the first vertex) vertex. If there is no more than one edge between any two vertex, it is called simple path. A circuit, on the other hand, is a path which get backs to the first point.
- An undirected graph is called connected if there is a path between every pair of distinct vertices in the graph. If there is only one vertex, it is also said to be connected. In directed graphs, strongly connected means the connections are bi-directional, weakly connected means they are not bi-directional.
- Dijkstra's algorithm is an iterative procedure that finds the shortest path between to vertices $a$ and $z$ in a weighted graph. You can find the explanation of how it works in week 11 lecture 2.
Trees
-
A tree is a connected undirected graph with no simple circuits. It also means that a tree cannot contain multiple edges or loops.
-
An undirected graph is a tree if and only if there is a unique simple path between any of its vertices.
-
Forest is two or more trees.
-
A tree together with its root produces a directed graph called a rooted tree.
-
The ancestors of a vertex other than the root are the vertices in the path from the root to this vertex, excluding the vertex itself and including the root. The descendants of a vertex $v$ are those vertices that have $v$ as an ancestor.
-
A vertex of a tree is called a leaf if it has no children.
-
The level of a vertex $v$ in a rooted tree is the length of the unique path from the root to this vertex. The level of the root is defined as zero. The height of a rooted tree is the maximum of the levels of vertices.
-
A rooted three is called an m-ary tree if every internal vertex has no more than $m$ children. The three is called a full m-ary tree if every internal vertex has exactly $m$ children. An m-ary tree with $m=2$ is called a binary tree.
-
A tree with $n$ vertices has $n-1$ edges.
-
A full m-ary tree with $i$ internal vertices contains $n = m\cdot i + 1$ vertices.
Spanning Trees
-
A spanning tree of simple graph G is a sub-graph of G that is a tree containing every vertex of G. A graph of $n$ vertices will have a spanning tree has $n-1$ edges/connections.
-
A minimum spanning tree in a connected weighted graph is a spanning tree that has the smallest possible sum of weights of its edges.
-
Prim's Algorithm:
- Firstly choose any edge with smallest weight and put it into the spanning tree.
- Successively add edges of minimum weight that are incident to a vertex already in, to the spanning tree. Don't create circuits.
- Stop when $n-1$ edges have been added.
-
Kruskal's Algorithm: It is same as Prim's but does not force you to check only incident ones.
Boolean Algebra
- It provides operations in the set ${0, 1}$.
- Three operations is mandatory to learn in this course: Boolean complementation, Boolean sum and Boolean product.
- Complement is denoted by bar.
$$
-0 = 1, -1 = 0
$$ - Boolean sum is denoted by $+$ or $OR$ operators,
$$
1+1 = 1, \ 1+0=1, \ 0+1=1, \ 0+0=0
$$ - Boolean product is denoted by $\cdot$ or $AND$,
$$
1\cdot 1 = 1, \
1\cdot 0 = 0, \
0\cdot 1 = 0, \
0\cdot 0 = 0
$$ - The variables $x$ only called a Boolean variable if it assumes values only from $B = {0, 1}$.
- A function from $B^n$, the set ${(x_1, x_2, ..., x_n) | x_i \in B, 1 \le i \le n}$, to B is called a Boolean function of degree n.
- Each Boolean expression represents Boolean functions.
- A literal is a Boolean variable or its complement. A minterm of the Boolean variables $x_1, x_2, ..., x_n$ is a Boolean product of $y_1y_2...y_n$ where $y_i = x_i$ or $y_i = -x_i$.
- Two different Boolean expressions that represent the same function are called equivalent.
- There are $2{2n}$ different Boolean functions for degree $n$.
| Identity Name | AND Form | OR Form |
|---|---|---|
| Identity Law | 1x = x | 0 + x = x |
| Null Law | 0x = 0 | 1 + x = 1 |
| Idempotent Law | xx = x | x + x = x |
| Inverse Law | x (-x) = 0 | x + (-x) = 1 |
| Commutative Law | xy = yx | x+y = y+x |
| Associative Law | (xy)z = x(yz) | (x+y)+z = xy+xz |
| Distributive Law | x + yz = (x+y)(x+z) | x(y+z) = xy+xz |
| Absorption Law | x(x+y) = x | x + xy = x |
| DeMorgan's Law | -(xy) = -x + -y | -(x+y) = (-x)(-y) |
| Double Complement Law | -(-x) = x | -(-x) = x |